Our approach is presented as a neural
network-based modular architecture for controllers, trained by a
neuro-evolutionary learning method, for robotic systems composed of
multiple sensors and actuators. Our method has the following advantages:
1. By evolving modules separately, the search space dimension that the
evolutionary algorithm has to afford is significatively reduced. This
is what staged evolution attempts to accomplish.
2. At each new stage, the newly added modules will start evolving not
from a random position in the search space, but from a place related to
the new task to be evolved, which makes it easier to obtain the desired
behaviour. This is what incremental evolution sets out to accomplish.
The DAIR method therefore combines both
techniques (staged evolution and incremental evolution) into a single
method, obtaining what we call as progressive design. The method is
also general in terms of both robot and task.
Drawbacks for highly complex robots
1. When the number of modules is so
large, it can be difficult to identify precisely which modules to use
to start the evolutionary process, and which type of task to assign to
them.
2. When the number of elements in the
controller increases, the newly added modules in the last stage will
have to interface with many previously evolved modules.
3. The use of a staged mechanism can lead to sub-optimal solutions.
This section discusses the use of the
DAIR approach as paradigm for the solution of other related problems.
DAIR and scale-up in evolutionary robotics
One of the biggest problems that
Evolutionary Robotics faces at present is that of scaling up, that is,
the use of ER in complex robots. To avoid this pitfall, the DAIR
architecture can be introduced as a solution.
Tactical modularity for resolution of general problems
Up until this point, the concepts of
strategic and tactical modularity have only been applied to the control
of robots. However, a step backwards can be taken to gain a wider
perspective, and apply those concepts to more general problems where no
devices exist, only abstract concepts or variables. Above all, it
implies the use of DAIR for the optimization of functions, that is, to
define the sub-goals required to generate a goal (strategic modules),
and then to create tactical modules for the elements that appear in
every sub-goal. We understand elements as the inputs required to
generate the sub-goal, such as the sensors modules, and the outputs
that define the sub-goal solution, like the actuator modules.
Tactical modularity and the robot inner world
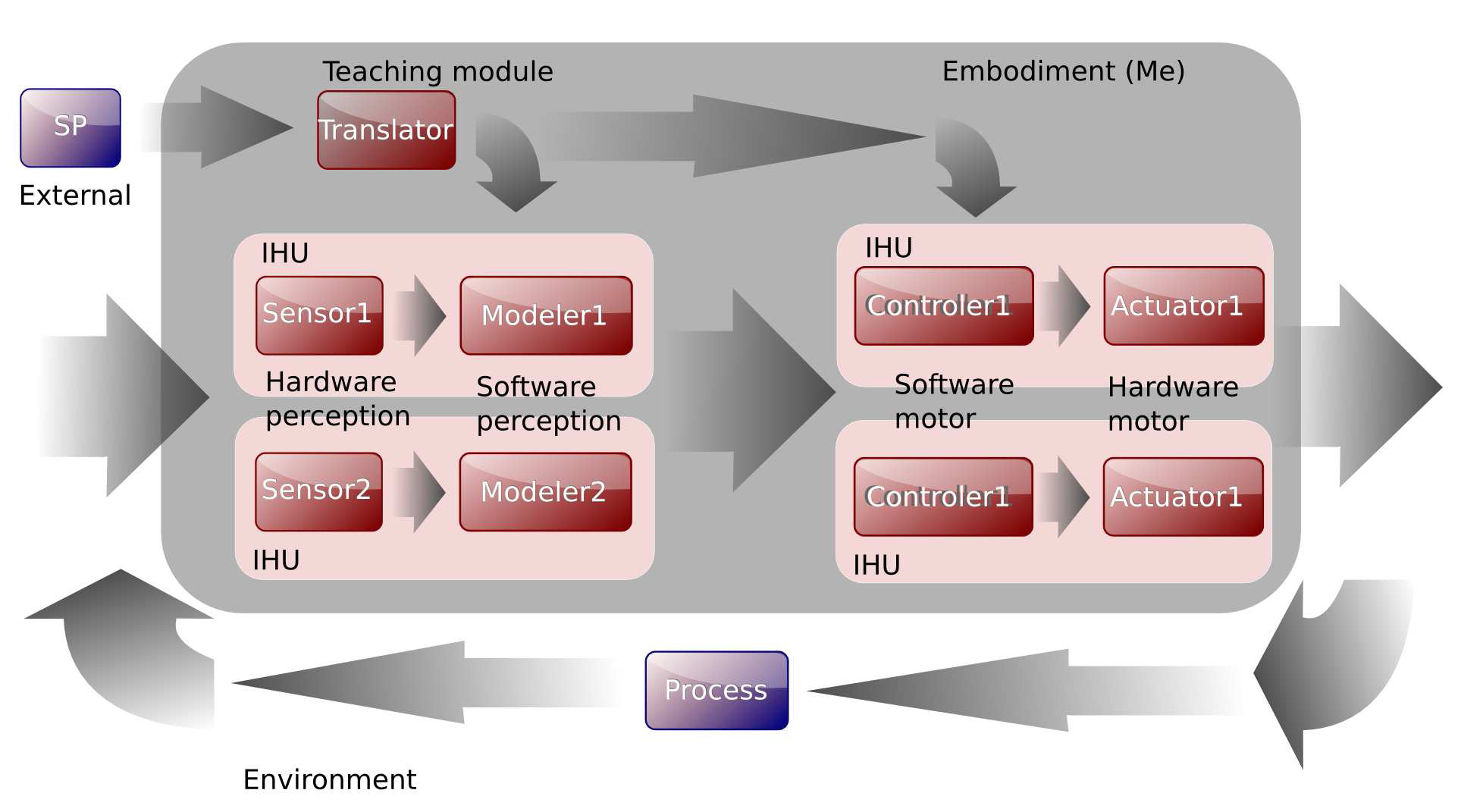
The proposed IHU-based tactical
modular architecture can be seen as a dynamical system approach to
cognitive robotics using a controlled engineering perspective .Our
claim is that the proposed network structure of IHU’s provides the
autonomous agent with an inner world based on internal representations
of perception rather than an explicit representational model, following
the ideas of internal robotics in [Parisi, 2004] and the double closure
scheme in [von Foerster, 1970]. In this architecture the concept of
double closure is completely obtained, and sensors and actuators are
completely coupled.
Figure 1: The ”Mind” designed through collaborative IHU’s in the form
of a
MIMO and the decentralized control architecture
Tactical modularity can be used to
implement a completely coupled walking system between sensors and
actuators, where the reflex system would be embedded into the walking
mechanism. The walking system, mainly driven by the actuator signals,
would have a directly coupled reflex system which is not a separated
part of the walking, but rather an integrated part of it. It is
suggested that animals have such type of a walking mechanism in order
to improve their walking behaviour.
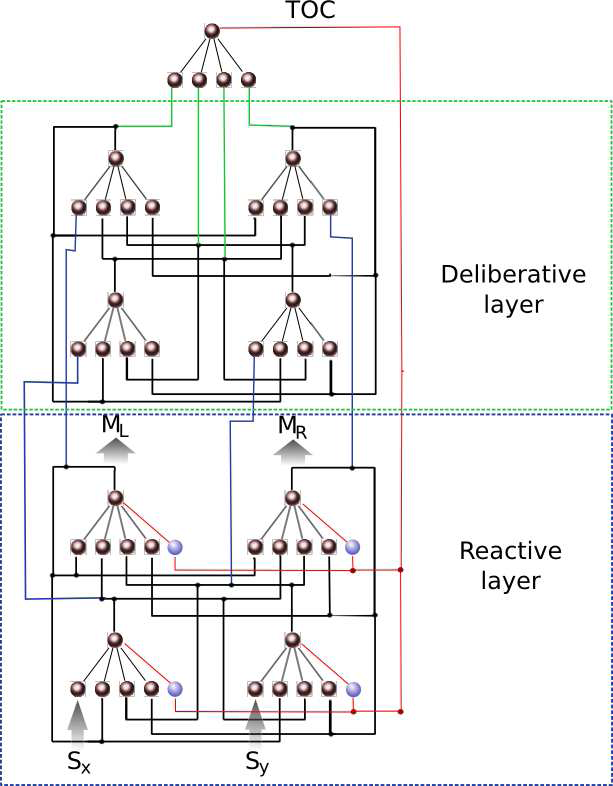
Deliberative control
It is possible to design a higher
control layer which reads the current state of the reactive tactical
structure, and then decides how to modify its behaviour through the use
of a tonic signal. Deliberation of the higher layer would be based on
the performance and current task required for the robot. This would
include the capacity to deliberately control complex robots using only
ANN’s in the DAIR architecture.
Figure 2: A deliberative structure using tactical modules.
Figure 3: Preliminary simulation created to implement a deliberative
solution for
the Aibo robot in the T-Maze experiment (thanks to Francesc Espasa for
actually implementing it).
Liar IHU’s
To date, IHU modules have been
desgined with a single output, which is used either for action in
actuator-IHU’s, or as a processed sensor value in sensor-IHU’s.
However, it could be interesting to investigate whether the
architecture improves in both learning rate and fitness value if each
IHU is allowed to have two or more outputs. The IHU would use one
output for its related purpose, and the second one to communicate a,
perhaps, different bit of information to the rest of IHU’s.
Web page by R. Téllez using rubric css by Hadley
Wickham
Don't undertake a project unless it is
manifestly important and nearly impossible (Edwin Land)